- Methods for Big Data
Research
Research Interests
At MBD, we explore a question that's more relevant than ever in today's data-driven world: How can we design innovative, reliable, and generalizable methods to handle massive datasets and solve complex problems?
Our lab specializes in Bayesian learning methods, a powerful approach that allows us to incorporate prior knowledge into models, quantify uncertainties, and bring more clarity to the “black boxes” of machine learning. For example, we leverage expert insights or sparsity-inducing mechanisms to make models more accurate, robust, and data-efficient. By fusing the precision and reliability of Bayesian Statistics with the adaptability of Machine and Deep Learning, we aim to deliver the best of both worlds.
Our research spans theoretical analysis, method development and real-world applications. For instance, some of our members craft new priors, others develop scalable and trustworthy Bayesian neural networks, and some advance explainability of complex systems. On the application side, our methods include diverse fields—from analyzing complex biomedical data and predicting weather patterns to improving autonomous driving technologies.
Below you can find a selection of topics that we are working on.
-
Big Data Methods
The age of digitalization has lead to complex large-scale data that are too large or infeasible for traditional statistical methods, e.g., due to unstructured information such as videos. We develop algorithms and software that can address these challenges and that lead to fast and accurate estimation even for data with many observations or complex structures.
-
Bayesian Computational Methods
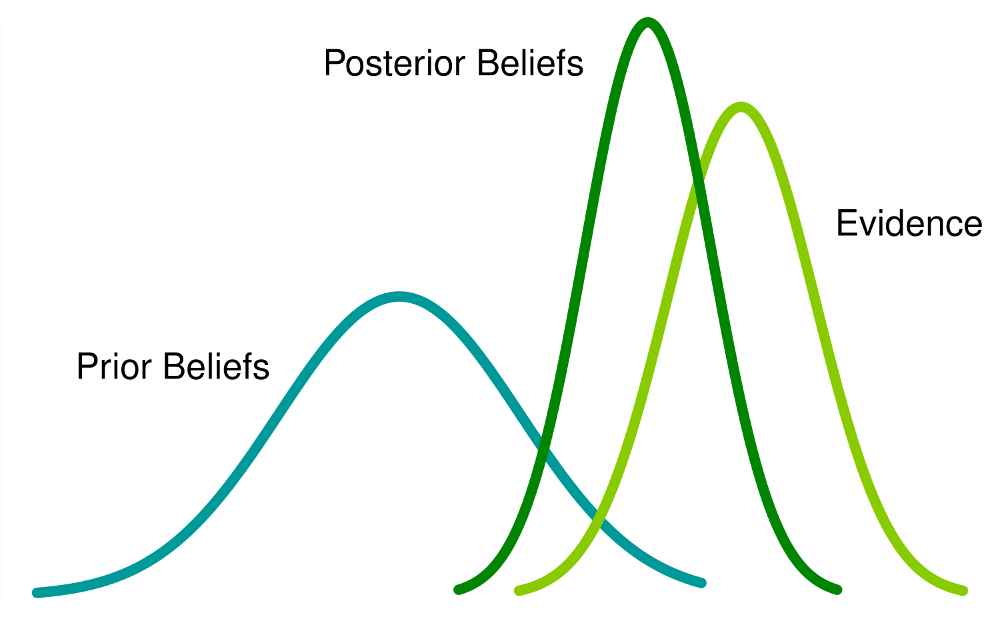
Bayesian computation is a powerful framework for tackling complex statistical problems. Our expertise lies in Markov Chain Monte Carlo (MCMC), Variational Inference, INLA and Approximate Bayesian Computation, which are used for estimating or approximating complex and high-dimensional posterior distributions with precision. By means of Bayesian principles, our methods excel in applications such as machine learning, data analysis, and decision-making under uncertainty. We specialize in modeling uncertainty and integrating prior knowledge seamlessly with data, providing a solid foundation for robust statistical analysis.
-
Bayesian Deep Learning
Bayesian Deep Learning is a state-of-the-art fusion of deep neural networks with Bayesian computational methods. There, we not only harness the power of neural networks for tasks like image recognition and natural language processing, but we also incorporate Bayesian principles. This means we can quantify uncertainty in predictions, improve model robustness, and enable reliable decision-making. Our research covers Bayesian neural networks, Bayesian optimization, and probabilistic programming to create models that not only make accurate predictions but also provide probabilistic measures of confidence in those predictions.
-

Copula Modelling and Regression Copulas
Copula modelling allows to characterize the joint distribution of multiple variables through a decomposition that separates modelling the marginal distributions and the dependence structure. This allows to study and model various forms of dependence, such as tail dependencies and non-linear relationships. Regression copulas further enhance this framework by incorporating regression structures through implicit copula processes, thereby enabling to model not only dependencies but also how they vary with covariates.
-
Distributional Regression
Distributional Regression is a cutting-edge statistical framework that goes beyond traditional mean regression models. We aim to model the entire distribution of the response variables, rather than just its mean. This enables us to capture richer and more nuanced information about the data, allowing for better insights and predictions. We leverage techniques such as quantile regression, conditional transformation models or regression copulas to accurately estimate the underlying conditional distributions as functions of structured but also unstructured input variables. Structured variables include classical tabular data, group-specific effects or spatial information and unstructured data can be images or text. Our research group specializes in developing and advancing Distributional Regression methods, exploring their applications in diverse fields, including economics, finance, and environmental science.
-
Network Analysis
Network analysis involves the study of complex systems involving connections between entities. When combined with probabilistic methods, it becomes a powerful tool for understanding uncertainty and relationships within real-world networks. We use techniques like Bayesian networks, Markov random fields, and probabilistic graphical models to capture dependencies, predict outcomes, and infer hidden information within networks to understand it better as a whole. By unveiling hidden patterns in these structures, ultimately decision-making in complex interconnected systems can be enhanced.
-

Real-World Object Detection
Real-world object detection faces challenges such as lighting variations, occlusions, scale disparities, and cluttered backgrounds. At MBD, we develop probabilistic models that leverage Bayesian deep learning to enhance detection with uncertainty estimation. Our research focuses on improving robustness and safety while maintaining high performance, particularly in data-scarce or noisy environments, including autonomous driving, medical imaging, and industrial inspection. To address the high cost and inefficiency of manual annotation, we also develop automated labeling strategies that leverage self-supervised, semi-supervised, and active learning. These approaches enhance data efficiency, minimize annotation overhead, and improve model generalization, enabling reliable deployment in diverse real-world scenarios.
-
Smoothing, Regularization and Shrinkage
Regularization and model selection are crucial in modern statistics, enhancing interpretability, preventing overfitting, and improving predictions. We integrate basis expansions with conditionally Gaussian regularization priors for smoothing. We also develop domain-specific shrinkage and variable selection priors, such as mixtures of Gaussian processes and latent binary processes. Understanding priors’ behavior and providing techniques to elicit their hyper-parameters plays a central role in our research. Moreover, we study the theoretical guarantees of the proposed Bayesian methods, such as contraction rates and model selection consistency. Finally, we apply these methods across diverse fields, including economics, climatology, and neuroscience.
-
Spatial Statistics
Spatial statistics focuses on analyzing and understanding spatial data and is applied to various disciplines such as urban planning, epidemiology, environmental science, resource management, etc. At MBD, we leverage state-of-the-art Bayesian methodologies to develop new flexible spatial statistical models for both the bulk and the tail (extremes) of the data and propose new efficient inference methodologies for existing models. These new methodologies allow us to gain insights into spatial dependencies and generate more reliable spatial predictions.