
- Methods for Big Data
Leveraging Informative Priors for Robust and Data-Efficient Motion Prediction
By Christian Schlauch and Nadja Klein, posted on March 13, 2025We are excited to share insights from our joint research with the Continental Automotive AG, which resulted in two published papers, which can be found here and here. The accompanying code is available on GitHub.
What is the paper about?
In our research we developed an informed learning approach to integrate explicit knowledge about traffic rules into deep learning motion prediction models for autonomous driving. We investigated easily scalable, computationally efficient realizations and demonstrated increased robustness and data-efficiency on public benchmark datasets.Motivation
Predicting the movement of surrounding traffic participants is crucial for the decision-making in autonomous driving systems. Uncertainty-aware, accurate motion prediction is a cornerstone to enable safe and comfortable driving. Current state-of-the-art deep learning motion prediction models have demonstrated impressive capabilities in capturing the complex interactions and ambiguities of traffic scenes. However, a major challenge remains:🚗 Deep learning models require vast amounts of expensive data to generalize robustly.
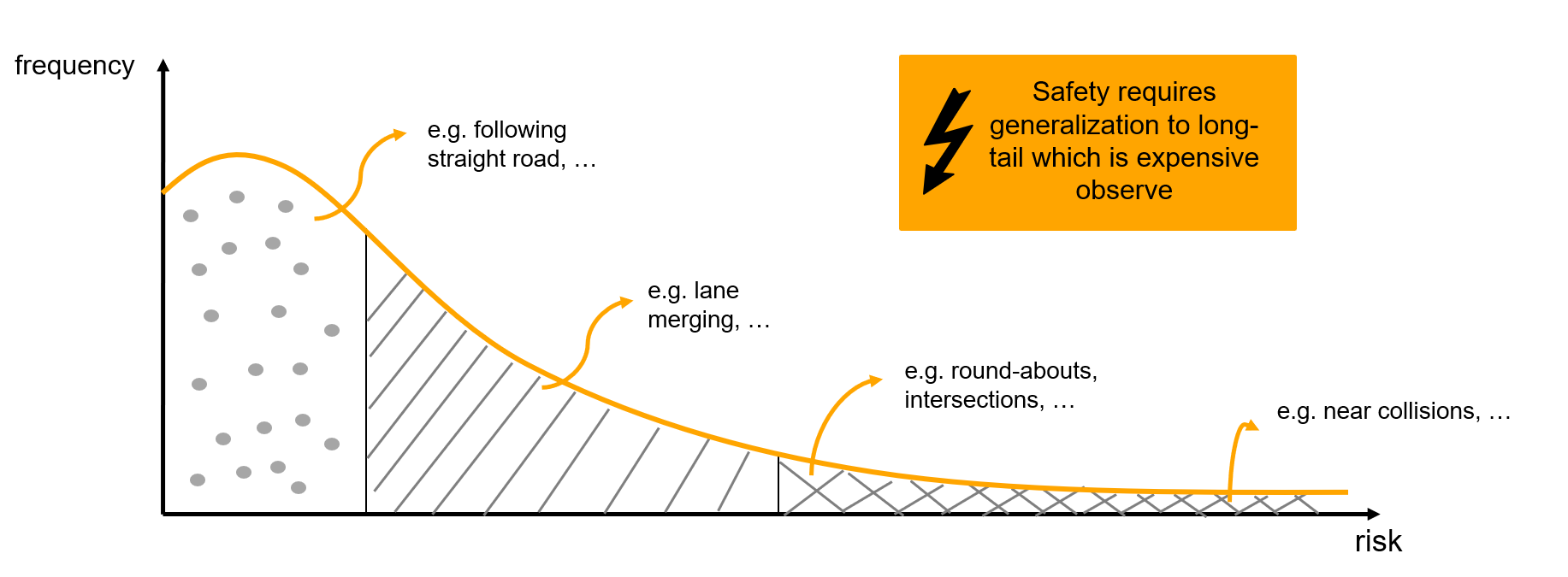
Prior work has focused on incorporating physical constraints to address this issue. However, there is another essential source of structure in driving: traffic rules. Traffic rules provide rich semantic context that can inform motion prediction about compliant behavior.
Theory
Our approach maps traffic rules onto synthetic training labels. Additionally, we employ Bayesian deep learning methods to enhance state-of-the-art motion prediction models. This enables us to learn informative priors from the synthetic labels (knowledge tasks), which, in turn, regularize training on observed data (conventional tasks).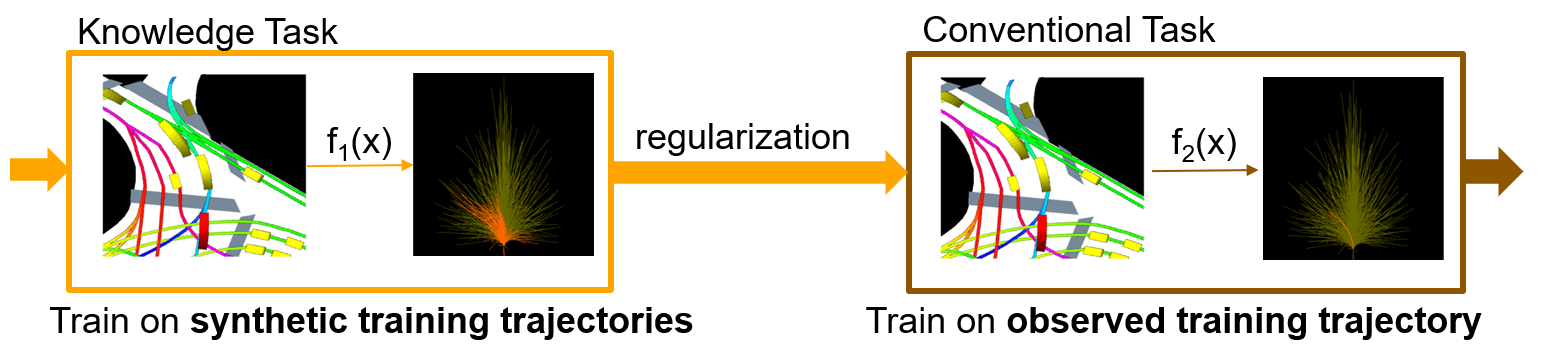
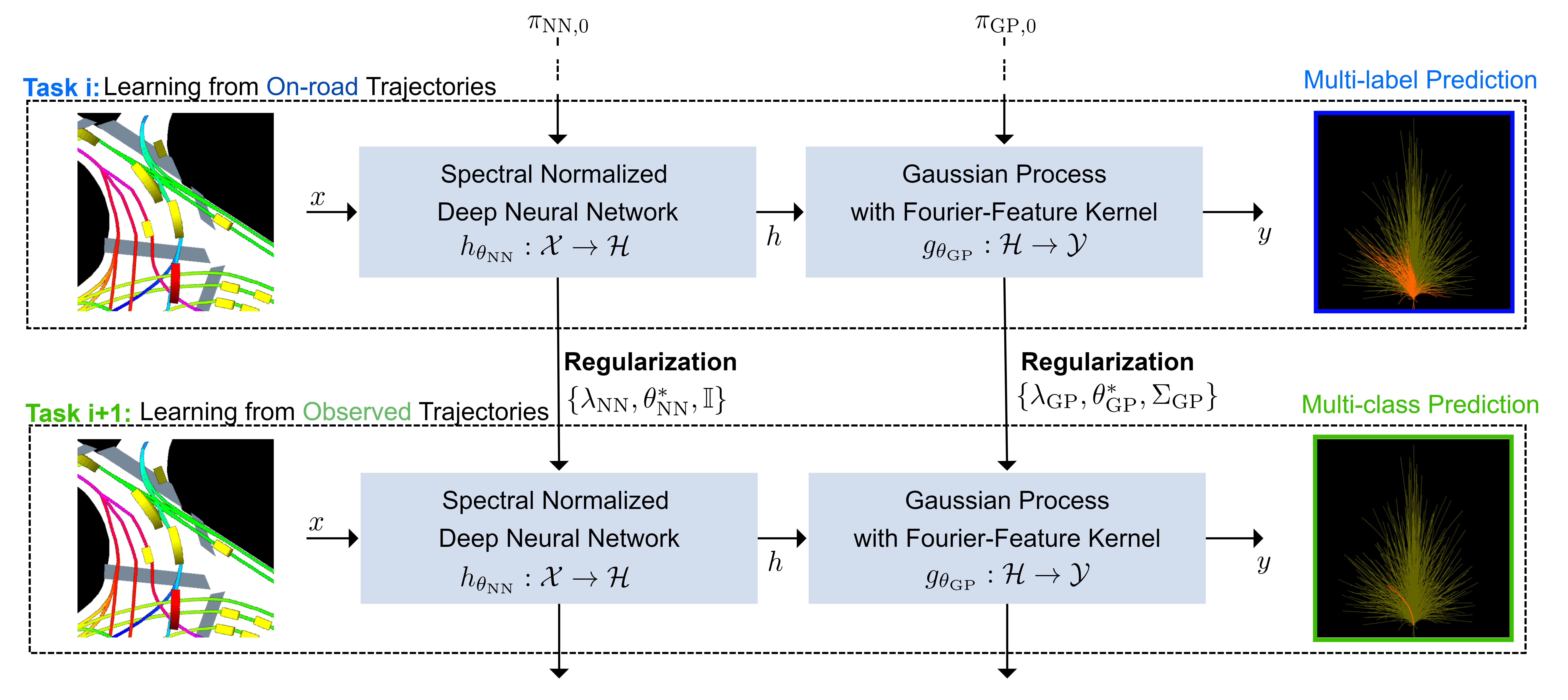
Specifically, we employ two probabilistic approximations and respective regularizations:
✅ A variational approximation over all layers of the model, using generalized variational continual learning (GVCL) as regularization method
✅ A compute-efficient last-layer Gaussian process (GP) with spectral normalized feature extractor, using a tailored regularization method leveraging a Fourier feature approximation for GPs
Experiments
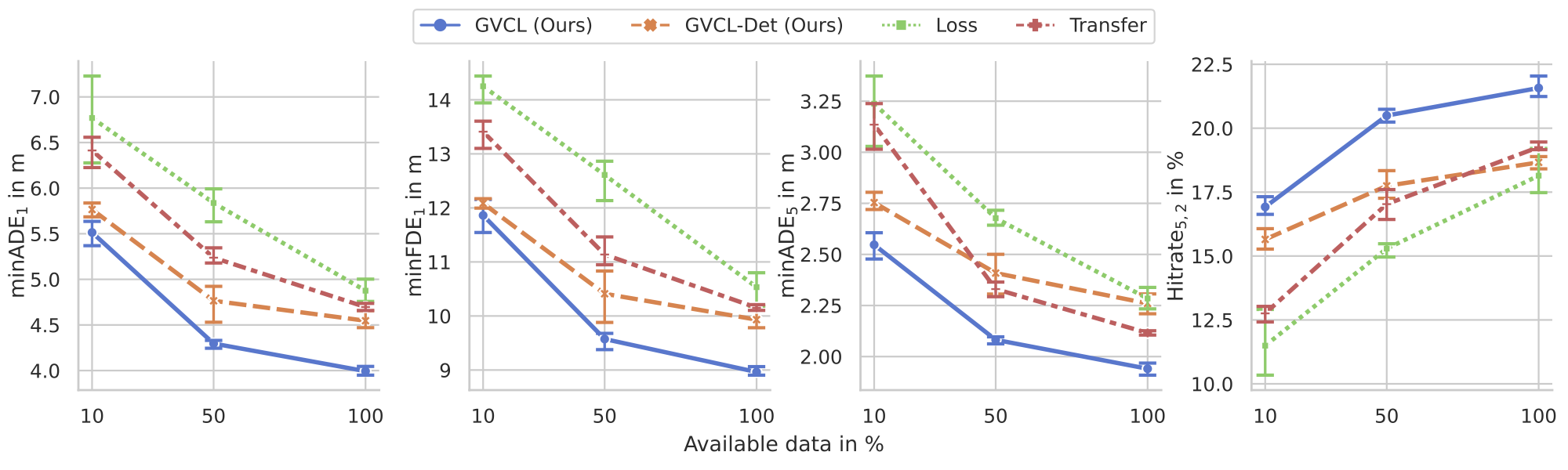
We evaluate our approach on two deep learning motion prediction models: CoverNet and MulitPath. Using two public benchmarks datasets, NuScenes [1] and Argoverse 2 [2], we demonstrate that our approach leads to:📊 Significant improvements in data efficiency — with far less data required to achieve competitive performance.
📍 Better location generalization — with increased robustness when applied to new, unseen environments.
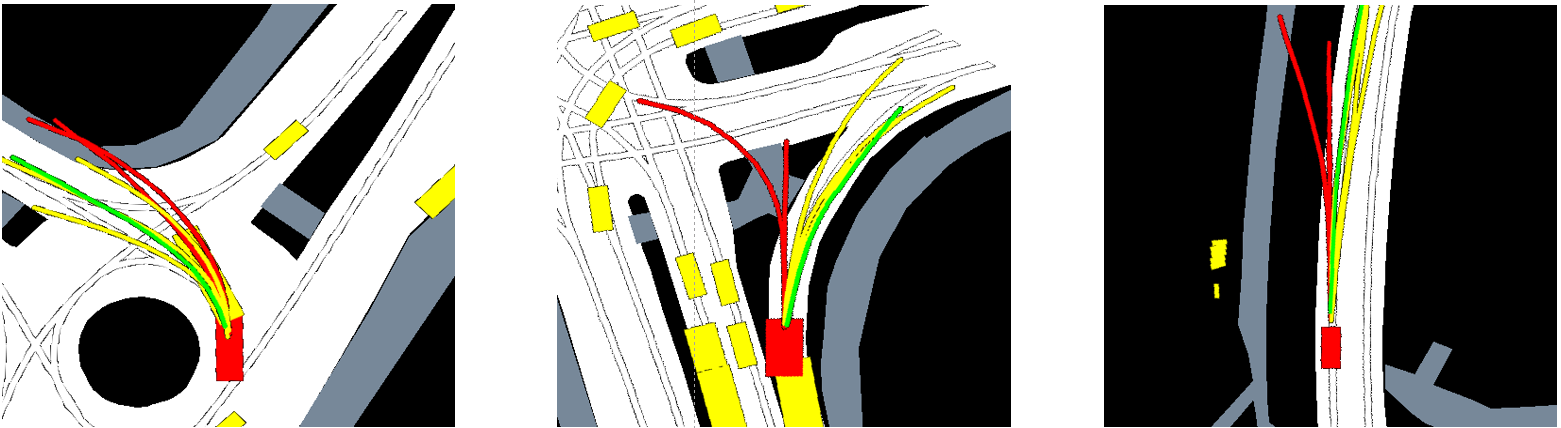
Final Thoughts
This research highlights the power of informative priors in improving deep learning models, requiring minimal architectural modifications and computational overhead. We are excited about exploring their potential in other domains and applications of deep learning in the future. If you are interested and want to try it out yourself, check out our GitHub and reach out if you have questions!References
[1] Caesar H., Bankiti V., Lang A. H., et al. (2020). nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition; 11621-11631.[2] Wilson B., Qi W., Agarwal T., et al. (2023). Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting. arXiv preprint arXiv:2301.00493.
For questions, comments or other matters related to this blog post, please contact us via kleinlab@scc.kit.edu.
If you find our work useful, please cite our paper:
@inproceedings{SchKleWir2023,
title={Informed Priors for Knowledge Integration in Trajectory Prediction},
author={Christian Schlauch and Nadja Klein and Christian Wirth},
year={2023},
booktitle={European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD)},
doi={10.1007/978-3-031-43424-2\_24},
pages={392--407},
}
@inproceedings{SchWirKle2024,
title={Informed Spectral Normalized {G}aussian Processes for Trajectory Prediction},
author={Christian Schlauch and Christian Wirth and Nadja Klein},
year={2024},
booktitle={27th European Conference on Artificial Intelligence (ECAI)},
doi={10.3233/FAIA240843},
volume={392},
pages={3023--3030},
}